De lo Local a lo Global: Un Análisis Profundo de GraphRAG
El sistema RAG (Retrieval-Augmented Generation) se consolidó como el estándar de la industria para mitigar las alucinaciones de los modelos de lenguaje grandes (LLMs), inyectando datos confiables durante la generación de respuestas. El mecanismo es conocido: ante una consulta, el sistema busca fragmentos de texto (“chunks”) relevantes en una base de datos vectorial y los pasa como contexto al modelo para que formule una respuesta fundada. Este enfoque demostró ser efectivo para preguntas puntuales sobre datos específicos. Sin embargo, su rendimiento decae significativamente cuando la tarea requiere una comprensión transversal de un corpus completo, como responder "¿Cuáles son los patrones de evolución tecnológica en estos 10.000 informes?". La recuperación por similitud vectorial, al entregar piezas aisladas, carece de la arquitectura necesaria para sintetizar un panorama global.
GraphRAG, presentado por Microsoft Research en el paper “From Local to Global: A GraphRAG Approach to Query-Focused Summarization”, aborda esta limitación proponiendo una estrategia diferente: estructurar la información en un grafo de conocimiento jerárquico antes de recibir cualquier consulta. Este proceso de indexación exhaustiva transforma los documentos fuente en una red de entidades y relaciones, agrupadas en comunidades temáticas, cada una con su propio resumen generado. Así, cuando llega una pregunta global, el sistema ya cuenta con un mapa semántico del corpus listo para ser navegado.
A continuación, analizamos las seis etapas de este pipeline, explicando cómo cada una alimenta a la siguiente y por qué el conjunto resulta más potente que la suma de sus partes.
El Pipeline de Indexación
El corazón de GraphRAG está en su fase de indexación. A diferencia de un sistema RAG tradicional, donde la inversión computacional se concentra en el momento de la consulta, GraphRAG realiza un trabajo pesado previo para facilitar las respuestas posteriores. Este trabajo consiste en construir, a partir de los documentos crudos, una estructura de conocimiento jerárquica que permita razonar sobre el dataset de forma transversal.
Etapa 1: Segmentación de Texto
El proceso inicia convirtiendo los documentos fuente en unidades de texto procesables, denominadas “TextUnits” o chunks. La decisión sobre el tamaño de estos fragmentos es una variable de ingeniería crítica, dado que afecta tanto el costo (cantidad de llamadas al LLM) como la calidad de la extracción posterior. GraphRAG recomienda fragmentos de aproximadamente 600 tokens, un tamaño que equilibra la retención de contexto local con la eficiencia del procesamiento.
El diagrama representa la transformación del documento original en múltiples fragmentos. La división respeta, en la medida de lo posible, los límites semánticos del texto, evitando cortar oraciones o párrafos a la mitad.
Un aspecto fundamental de esta segmentación es el solapamiento entre fragmentos. Al repetir aproximadamente 100 tokens entre el final de un chunk y el comienzo del siguiente, el sistema genera una continuidad semántica. Esta superposición garantiza que las relaciones que cruzan los límites de un fragmento (por ejemplo, una mención de “la empresa mencionada anteriormente”) no queden huérfanas de contexto. Así, cuando en la etapa siguiente el LLM analice cada chunk de forma aislada, contará con la información necesaria para interpretar correctamente las referencias internas del texto.
Etapa 2: Extracción de Elementos
Una vez segmentado el corpus, cada chunk es procesado por un LLM con el objetivo de extraer tres tipos de elementos estructurados: entidades (que serán los nodos del grafo), relaciones (que serán las aristas) y claims (afirmaciones fácticas que anclan el conocimiento a la fuente).

La figura ilustra este proceso de destilación. Los fragmentos de texto ingresan al modelo y emergen como componentes estructurados: íconos que representan entidades clasificadas (Persona, Organización, Evento, Tecnología) y flechas que describen relaciones entre ellas (“trabaja_en”, “desarrollado_por”, “colabora_con”).
El prompt utilizado para esta extracción es multipartite: instruye al modelo para que identifique entidades, las clasifique en categorías predefinidas, y describa explícitamente la naturaleza de sus vínculos. Para maximizar la cobertura, GraphRAG implementa una técnica de “gleaning” (rebusque): tras la primera pasada de extracción, el sistema ejecuta un continuation prompt preguntando al modelo si quedó algún elemento sin capturar. Esta iteración adicional reduce significativamente la pérdida de información.
La calidad de este proceso mejora sustancialmente cuando se utilizan prompts few-shot adaptados al dominio específico. Inyectar ejemplos de extracción correcta (por ejemplo, de reportes financieros o papers biomédicos) sesga al modelo hacia el tipo de entidades y relaciones relevantes para el corpus. Además, la extracción de “claims” permite conservar el contexto factual original: cada relación queda anclada a una cita del texto fuente, con fecha si está disponible, lo que facilita la verificación posterior y reduce el riesgo de alucinación.
Etapa 3: Construcción del Grafo
Con miles de entidades y relaciones extraídas, el sistema enfrenta un desafío de consolidación: la misma entidad puede aparecer mencionada con distintas variantes (por ejemplo, “Juan Pérez”, “J. Pérez” y “el ingeniero Pérez” podrían referirse a la misma persona). GraphRAG aplica algoritmos de resolución de entidades para fusionar estas menciones duplicadas en un único nodo canónico, creando así un multigrafo unificado y coherente.
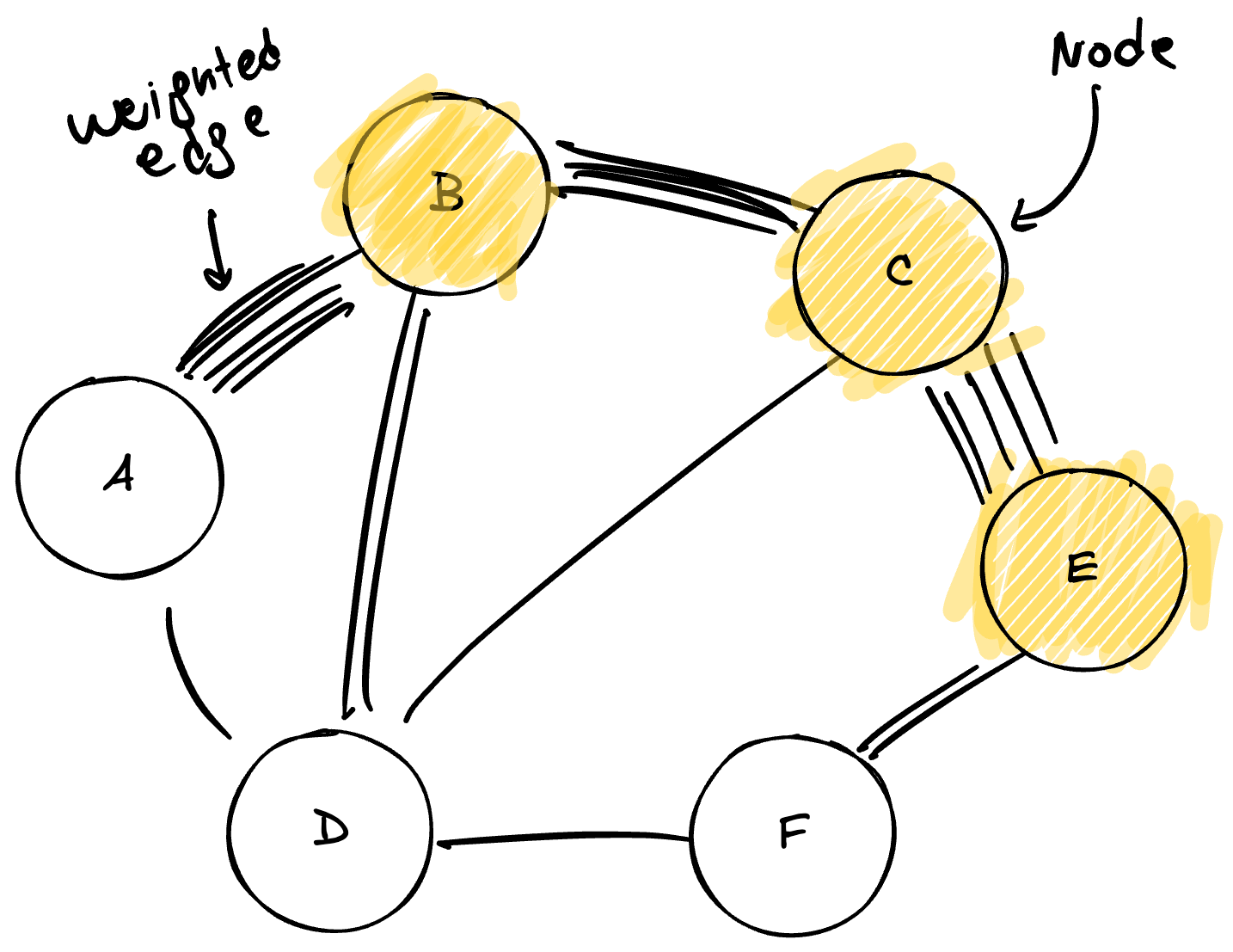
En el diagrama se observa la red consolidada. Los nodos más grandes (en naranja) representan entidades con alta centralidad, es decir, aquellas que participan en múltiples relaciones y actúan como hubs de información. Las líneas de mayor grosor indican relaciones que fueron detectadas en múltiples instancias a lo largo del corpus.
Este grosor de las aristas corresponde al concepto de peso ponderado. Cada vez que el sistema detecta una relación entre dos entidades en diferentes partes del corpus, incrementa el peso de la arista correspondiente. Una relación mencionada cincuenta veces tendrá un peso sustancialmente mayor que una mencionada una sola vez. Esta ponderación transforma al grafo en un mapa de calor de relevancia: permite distinguir vínculos estructurales profundos (aquellos que atraviesan múltiples documentos y contextos) de conexiones anecdóticas que aparecen de forma aislada. Este peso será el insumo principal para el algoritmo de detección de comunidades que sigue, ya que le indica cuáles nodos deberían agruparse juntos.
Etapa 4: Detección de Comunidades
El grafo resultante de la etapa anterior puede contener miles o millones de nodos, una escala que excede la capacidad de cualquier ventana de contexto de LLM. Para organizar esta información de forma navegable, GraphRAG aplica el algoritmo Leiden, un método de detección de comunidades que agrupa los nodos en clusters basándose en la densidad de sus conexiones.
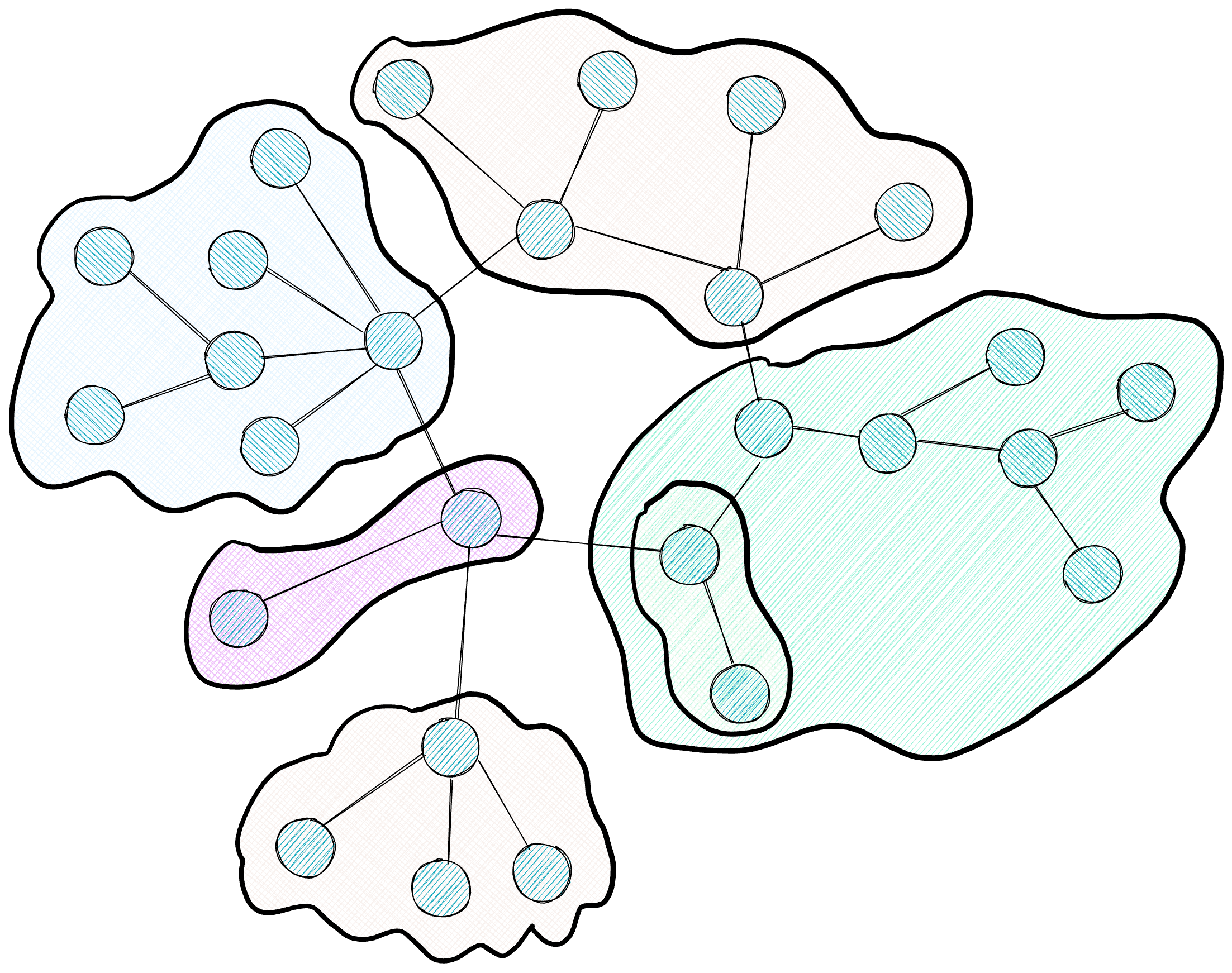
El diagrama muestra la jerarquía resultante: clusters de diferentes colores agrupan nodos densamente conectados entre sí, con líneas punteadas indicando los niveles superiores de la jerarquía que engloban a clusters más pequeños.
El algoritmo Leiden opera optimizando una métrica llamada “modularidad”, que mide qué tan densamente conectados están los nodos dentro de una comunidad en comparación con conexiones hacia afuera. Los pesos de las aristas calculados en la etapa anterior son cruciales para este proceso: Leiden utiliza esa información de intensidad para decidir qué nodos deben agruparse. Si dos nodos comparten una relación pesada (alta frecuencia de co-ocurrencia), el algoritmo los mantiene en la misma comunidad; si la relación es débil, permite que se separen.
Leiden se ejecuta de forma recursiva, generando una jerarquía de comunidades. El nivel superior (Nivel 0) contiene macro-temas que abarcan grandes porciones del corpus; cada uno de estos macro-temas se subdivide en subtemas más específicos (Nivel 1), y así sucesivamente hasta llegar a comunidades muy focalizadas. El algoritmo incorpora un parámetro de resolución (gamma) que permite ajustar esta granularidad: valores altos producen comunidades más pequeñas y específicas, mientras que valores bajos generan clusters más amplios. Esta flexibilidad permite elegir el nivel de detalle apropiado según la naturaleza de la consulta posterior.
Una ventaja técnica de Leiden sobre su predecesor Louvain es la incorporación de una fase de refinamiento. Tras una primera agrupación, Leiden verifica que cada comunidad esté internamente bien conectada, evitando que queden nodos aislados dentro de un cluster. Esta garantía de conectividad interna es fundamental para la etapa siguiente, porque asegura que cada comunidad representa un tema cohesivo, susceptible de ser resumido de forma coherente.
Etapa 5: Generación de Resúmenes de Comunidad
Con el grafo particionado en comunidades jerárquicas, GraphRAG genera un resumen textual para cada una de ellas. El proceso consiste en alimentar al LLM con todos los nodos y aristas de una comunidad y pedirle que redacte un reporte ejecutivo describiendo de qué trata ese cluster.
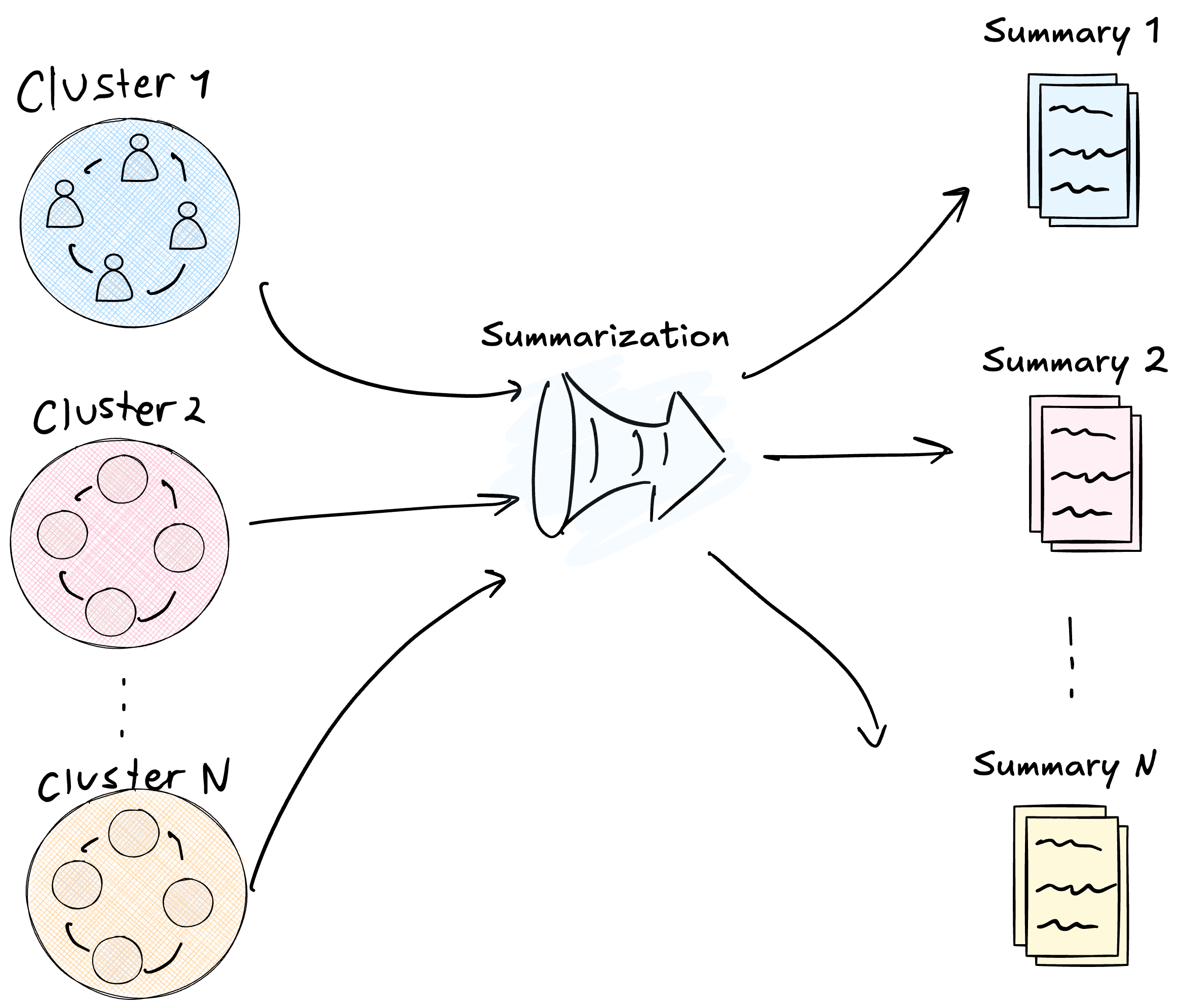
La figura muestra esta transformación: los clusters circulares (datos crudos del grafo) se comprimen en documentos de reporte (información procesada lista para consumir).
Estos resúmenes funcionan como un índice invertido semántico. Cuando posteriormente llegue una consulta, el sistema consultará estos reportes curados que ya condensan la información importante sobre cada tema. Este pre-cálculo offline tiene un beneficio fundamental: ancla al modelo en información verificada y destilada, reduciendo drásticamente el riesgo de alucinación. El LLM, al momento de responder, trabaja con resúmenes que ya pasaron por un proceso de extracción y validación, y que incluyen referencias a las fuentes originales.
Los niveles superiores de la jerarquía contienen resúmenes de resúmenes. El sistema procesa primero las comunidades de nivel más bajo (las más específicas), genera sus reportes, y luego utiliza esos reportes como insumo para generar los resúmenes de los niveles superiores. Así se construye una pirámide de abstracción donde la información fluye desde los datos granulares en la base hasta insights de alto nivel en la cima. Esta estructura permite navegar el corpus a diferentes niveles de detalle según las necesidades de la consulta.
Etapa 6: Generación de Respuesta Global
Cuando finalmente llega una consulta global que requiere sintetizar información de todo el corpus, GraphRAG debe decidir qué resúmenes de comunidad utilizar como contexto. Esta decisión puede realizarse de dos maneras.
La primera opción es utilizar un nivel jerárquico preestablecido. El operador del sistema define de antemano en qué nivel de la pirámide buscar: si se elige el Nivel 0 (macro-temas), el LLM recibirá pocos resúmenes muy amplios; si se elige un nivel inferior, recibirá más resúmenes pero más específicos. Esta configuración es útil cuando se conoce de antemano el tipo de consultas esperadas.
La segunda opción, más sofisticada, es la Selección Dinámica de Comunidades (Dynamic Community Selection o DCS). En este esquema, el sistema comienza desde la raíz del grafo jerárquico y utiliza el propio LLM para evaluar la relevancia de cada reporte de comunidad respecto a la consulta entrante. Si un reporte de alto nivel resulta irrelevante, el sistema poda ese subárbol completo sin descender a sus hijos; si resulta relevante, desciende recursivamente hacia niveles más específicos. Este mecanismo permite recolectar información del nivel de detalle apropiado para cada consulta, evitando tanto la generalización excesiva como el ruido de información irrelevante.
Una vez seleccionados los resúmenes relevantes, el sistema ejecuta un pipeline de procesamiento en dos fases: Map y Reduce.

El diagrama ilustra este flujo paralelo: múltiples fuentes (los resúmenes de comunidad) alimentan procesos independientes de generación de respuestas parciales, que luego convergen en una síntesis final.
En la fase Map, el sistema divide la pregunta para que sea respondida por cada comunidad relevante de forma aislada. Cada resumen de comunidad recibe la consulta y genera una respuesta parcial basada únicamente en la información contenida en ese cluster. Este enfoque garantiza que la evidencia se busque localmente, obligando al modelo a fundamentar cada afirmación en datos concretos de la comunidad.
En la fase Reduce, el sistema toma todas las respuestas parciales generadas en la fase anterior, las filtra por relevancia (asignando un puntaje de 0 a 100) y sintetiza las más pertinentes en una narrativa final cohesiva. Este proceso de filtrado es crucial: no toda comunidad tendrá información relevante para toda consulta, y el scoring permite descartar respuestas parciales que no aportan valor.
Este enfoque permite escalar la comprensión a datasets de cualquier tamaño. Al procesar las comunidades en paralelo, el sistema puede manejar corpus masivos simplemente agregando más nodos de cómputo. La estructura jerárquica también asegura equidad en la representación: un dato crucial contenido en un documento aislado tiene la misma oportunidad de influir en la respuesta final que un dato repetido en cientos de documentos, siempre que la comunidad correspondiente lo considere relevante y lo incluya en su resumen.
Complementariedad: La Búsqueda Local (Local Search)
El flujo que acabamos de describir, conocido como “Global Search”, es extraordinario para responder preguntas de alto nivel sobre la totalidad del dataset. Sin embargo, surge una pregunta natural: ¿qué sucede si necesitamos recuperar un dato extremadamente puntual, como la fecha exacta de un evento menor o el apellido de un personaje secundario? En estos casos, el enfoque global puede resultar ineficiente, ya que los resúmenes de comunidad tienden a generalizar y podrían omitir detalles microscópicos.
Para cubrir esta necesidad, el framework de GraphRAG incluye un mecanismo complementario denominado “Local Search”. A diferencia del barrido global, la búsqueda local utiliza las entidades extraídas como puntos de entrada precisos. Cuando el sistema recibe una consulta sobre una entidad específica, no recorre los resúmenes de comunidad, sino que navega directamente por el grafo, explorando los vecinos inmediatos de esa entidad y recuperando los fragmentos de texto originales (“TextUnits”) asociados.
Esta dualidad es la verdadera fortaleza de la arquitectura. Mientras que el modo Global ofrece sensemaking y síntesis de patrones, el modo Local garantiza precisión quirúrgica y recuperación de detalles. Ambos modos conviven sobre la misma estructura indexada, permitiendo al usuario alternar entre una visión panorámica y una lupa de aumento según la naturaleza de su pregunta, resolviendo así el compromiso histórico entre amplitud y profundidad en la recuperación de información.
Conclusión y Futuras Perspectivas
GraphRAG representa un cambio de paradigma en la forma de abordar la recuperación de información para LLMs, pero no está exento de desafíos importantes. El costo computacional de construir y mantener el grafo es sustancialmente mayor que el de una simple base de datos vectorial; cada nuevo documento requiere un proceso de extracción y re-indexación que, en la versión original, puede ser costoso y rígido. Además, la separación estricta entre modos “Global” y “Local” obliga muchas veces a tomar decisiones de diseño manuales sobre cuál pipeline ejecutar, en lugar de tener un sistema unificado que decida por sí mismo.
La industria, sin embargo, se mueve rápido. Nuevos frameworks como LightRAG y RAGAnything ya están iterando sobre estos conceptos para solucionar estas limitaciones, proponiendo esquemas de actualización incremental y modos híbridos nativos que fusionan lo mejor de ambos mundos en una sola llamada. Pero el análisis profundo de estas nuevas herramientas, y cómo logran bajar los costos manteniendo la calidad del razonamiento, será tema de nuestro próximo artículo.
Referencia: Edge, D., et al. (2024). From Local to Global: A GraphRAG Approach to Query-Focused Summarization. arXiv preprint arXiv:2404.16130. Disponible en: https://arxiv.org/pdf/2404.16130